
Momenta,这家在行业内被称为“物理AI第一股”的企业,即将登陆港交所。
与之相伴的,是一个官方反复提及的技术概念——世界模型。它被描述为“物理AI时代的基座模型”,被认为是激发物理AI“GPT时刻”的关键突破口。
这听起来宏大而令人振奋。
但面对这类“某某时刻”“基座模型”“范式革命”的叙事时,一些人可能会习惯性地追问几个更朴素的问题。
第一,所谓的“世界模型”,究竟是技术演进的全新成果,还是一个被精心包装的融资话术?
第二,“基座”这个词在AI领域已被广泛使用。如果说大语言模型的基座是海量文本,那么物理AI的基座凭什么是一个能预测视频下一帧的模型?它真的承载得起“物理世界的常识”这样一个深刻命题吗?
第三,我们真正在谈论的,究竟是技术本身,还是技术背后更加复杂的商业逻辑?
从这几个问题来看,Momenta IPO并非一个简单的融资事件。Momenta是“物理AI”这条赛道上,第一个接受公开资本市场检验的玩家。市场将用真金白银投票的,既是Momenta过去几年的发展成果,更是“世界模型作为物理AI基座”这一宏大叙事的未来预期。
模型“懂物理”,还有“练兵场”和“教练”
先正面回答一个问题:什么是世界模型?它和此前的AI模型,到底有什么区别?
用一个最简单的类比。数字AI时代,ChatGPT的伟大突破在于,它让机器掌握了语言的规律。它知道一句话怎么接下一句,知道上下文之间的逻辑关系,知道常识性的知识图谱,它压缩的是“文本世界的规律”。
物理AI时代需要的,则是一个能压缩“物理世界规律”的模型。它需要知道:一个球被踢出去会沿着抛物线飞行;一辆车急刹车时车身会前倾;两辆车在交叉路口相遇,谁应该让谁。这些在人类看来甚至不需要思考的常识,对于AI而言,恰恰是最难习得的部分。
世界模型要做的事情,就是把物理世界的规律——重力、惯性、因果、遮挡关系、运动轨迹——压缩进一个神经网络里,让模型“懂得”物理世界是如何运转的。
这个目标很清晰,但实现路径极其艰难。为什么?因为物理世界的数据,获取太难了。
文本数据唾手可得。互联网上有数以万亿计的网页、书籍、论文,这些是人类知识的海量数字化遗产。但物理世界的数据,例如一辆车在暴雨中行驶的视频、一个行人在十字路口突然折返的瞬间、一只流浪猫从路边窜出的场景,这些数据不仅难以获取,而且无法通过“爬虫”来批量采集。
更难的是“测试”。一个语言模型写错了答案,用户可以立刻发现并纠正。但一个自动驾驶模型如果判断失误,后果可能是真实的碰撞事故。物理AI的检验成本,比数字AI高出几个数量级。
正因为这个原因,世界模型长期停留在学术论文和实验室Demo阶段。直到最近,随着海量真实驾驶数据的积累、算力成本的下降、以及模型架构的演进,它才真正有了商业化的可能。
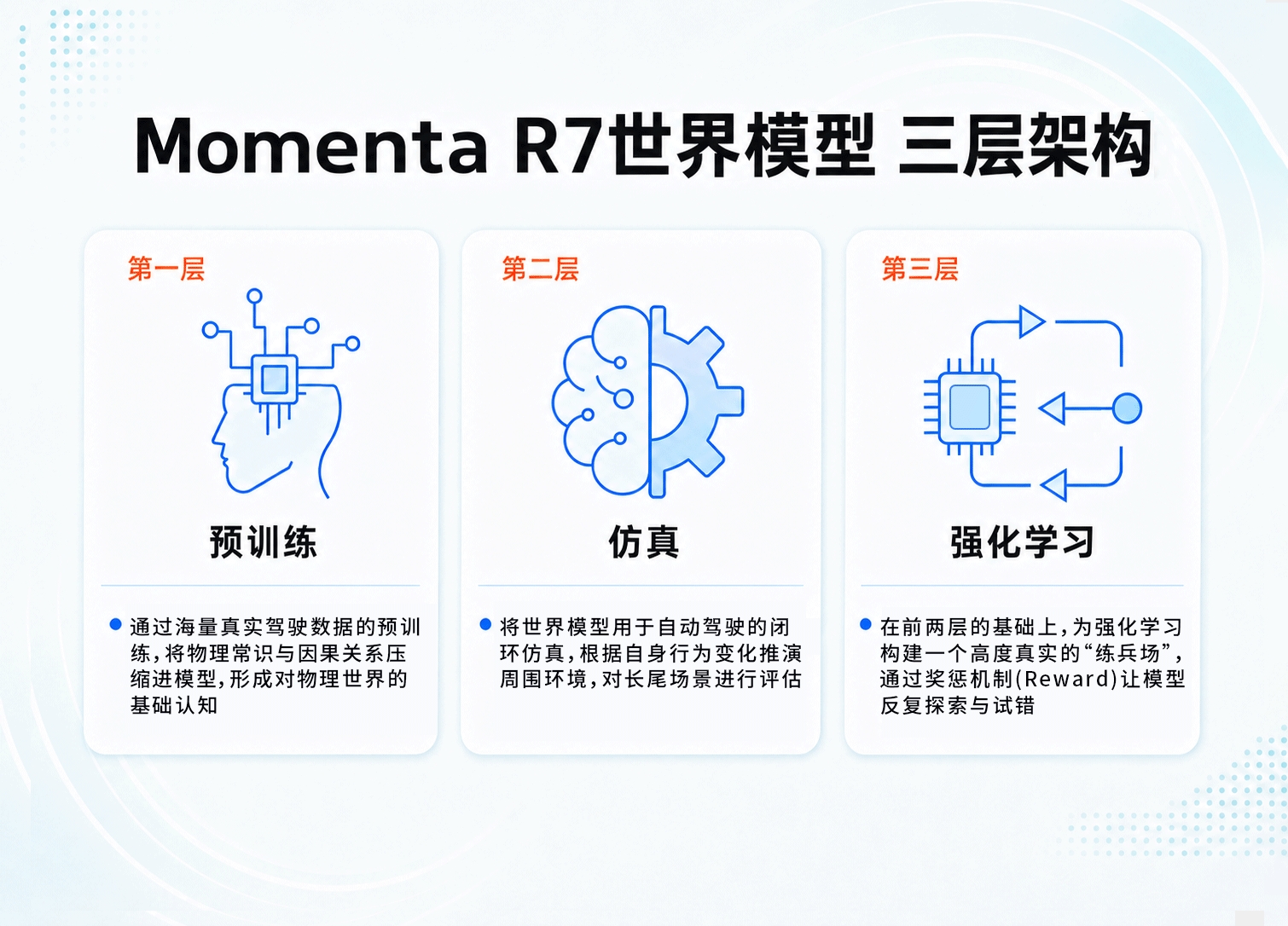
而Momenta R7世界模型的架构,被设计成了三层。每一层都在回应上述挑战中的某一个环节。
第一层是World Model Pre-Training,也就是让模型“懂物理”。
这一层的任务,是把海量真实驾驶数据中的物理常识与因果关系,压缩进基座模型。通俗地说,就是让模型看足够多的真实世界视频,先学懂物理。
第二层是World Model Simulation,也就是让模型拥有“练兵场”。
模型光“懂物理”还不够,它需要在一个安全的环境里反复验证自己的决策。这就引出了世界模型的第二层能力:闭环仿真。
传统仿真有一个致命问题:渲染生成的世界和真实世界之间存在巨大的“Sim-to-Real Gap”。你在游戏引擎里建一个十字路口,那是一个理想的、干净的、物理规则简化的世界。但真实的十字路口有坑洼的路面、有褪色的标线、有随意停靠的货车、有打伞的行人。模型在仿真里练得再好,一上路可能还是“懵”。
Momenta R7的做法是:利用从真实数据中学习生成的世界进行仿真。这意味着,仿真环境中的每一个场景元素,从每一棵树、每一辆车的行驶轨迹到每一个行人的动作,都来源于真实世界的采样,而非程序员想当然的预设。
更关键的是,Momenta通过实车和仿真的一致性来做对齐和校准,拥有明确可参考的benchmark,从而减少仿真与真实世界之间的差异性。
这套机制的价值,用一个数字就能说明:效率比传统实车路测提升了上万倍。换句话说,一个在真实道路上需要跑数十年才能遇到的极端场景组合,在R7的仿真环境里可能只需要几个小时就能遍历一遍。
第三层是World Model Reinforcement Learning,也就是让模型拥有“教练”。
懂了物理、有了练兵场,接下来是“学会开车”。这一层依赖的是强化学习。强化学习的本质是奖惩机制:模型做出正确决策就奖励,做出错误决策就惩罚。通过反复试错,模型逐步学会在复杂环境中输出最优策略。
Momenta在这一层的优势有两方面。
一是拥有真实世界里大量用户的反馈闭环。这意味着奖惩信号的来源,不是仿真环境里的模拟打分,而是真实道路上数十万用户的真实驾驶数据。
二是拥有更多的黄金数据,尤其是长尾场景数据。所谓“长尾场景”,就是那些发生概率极低、但一旦发生就极其危险的边缘情况。这些数据是强化学习中最宝贵的“教材”。
说到这里,一个追问不可避免:这套三层架构,与业内其他公司的世界模型方案,区别到底在哪?
答案在于“预训练”这个环节的定位。
业内普遍将世界模型用作仿真工具,也就是,先训练一个世界模型,然后用它来生成数据,再拿这些数据去训练或测试主模型。在这个路径里,世界模型是一个“辅助工具”,相当于考前给学生发了几套模拟试卷。
Momenta则是将世界模型直接应用于“端到端基座模型预训练”。它不是给学生发模拟卷,而是直接重塑了学生的大脑认知结构。模型从一开始就建立在“懂得物理世界规律”的基座之上,再通过仿真和强化学习进行微调。
这好比两个学生准备物理竞赛。一个学生通过大量刷题来积累经验;另一个学生先系统学习了牛顿力学、热力学、电磁学的全部理论框架,再通过做题来验证和巩固。前者的上限取决于题库的覆盖范围;后者的上限取决于物理定律本身,而物理定律是普适的、无界的。
Momenta R7选择的是后一条路。
但这并不是说前一条路就错了。只是两者对世界模型的定位完全不同,由此带来的系统上限和迭代速度也截然不同。Momenta认为,这种底层应用代差,让世界模型成为了一个超级“放大器”,使系统的整体产品性能和上限实现了10到100倍的代际跃升。
当然,这个“10到100倍”的实际效果,将取决于接下来几年的量产交付数据和用户反馈。但至少在逻辑上,这条路径是自洽的:用真实数据训练基座,用真实数据校准仿真,用真实用户反馈强化学习,每一个环节都锚定“真实”二字。
不仅是技术,更是两大“Scaling”的飞轮
一个值得追问的问题是:如果世界模型在技术逻辑上如此自洽,那为什么是Momenta率先把它做到量产上车,而不是其他公司?
2022年,Momenta完成首个10万台量产交付,用了24个月。而到了2026年,这个数字被压缩到不到40天。24个月到40天,这中间的跨度,堪称一种指数级的进化。
这种进化的驱动力,到底是什么?
一个常见的解释是“技术突破”。这肯定没错。R7世界模型的三层架构、端到端基座预训练、强化学习闭环,这些技术层面的演进,确实是产品性能跃升的直接原因。
招股书显示,2025全年,Momenta研发投入为18.69亿元,占其年度收入的77.5%,近三年累计研发投入达46.6亿元。截至2025年底,公司拥有研发人员1157名,研发人员占比近82%,超过三分之二拥有硕士及以上学历。
但是,如果我们只看到技术,就忽略了更底层的两个变量。
这两个变量,官方把它们总结为数据Scaling和商业Scaling。而Momenta真正的壁垒,在于自身同时跑通了这两个Scaling,并且形成了正反馈。
先说数据。
世界模型需要海量真实物理交互数据来预训练。这个“海量”的下限是多少?行业内没有统一标准,但一个共识正在形成:单纯靠仿真渲染生成的数据,无法替代真实道路上的物理反馈。因为仿真是对物理规律的“近似”,而真实道路是物理规律本身的“全集”。一个在近似中训练出的模型,一旦遇到近似之外的边缘情况,就会暴露出认知盲区。
Momenta的数据来源,是它搭载在量产车上的L2++辅助驾驶系统。这些车每天都在真实道路上行驶,持续采集各类驾驶场景。截至2026年,Momenta积累了120+亿公里的实车里程,从中提炼出了1亿段“黄金数据”。所谓“黄金数据”,指的是包含特定场景价值的高质量片段,比如复杂路口、恶劣天气、罕见障碍物、非常规驾驶行为等。
这个数字的意义,可以从两个维度来理解。
横向看,120亿公里是什么概念?地球到太阳的平均距离约为1.5亿公里。120亿公里相当于地球到太阳往返40次。这个体量的真实道路数据,是无法在短时间内通过任何方式“突击”采集的。每一公里都对应着一辆真实量产车的真实行驶时间。
纵向看,数据积累的速度在加快。Momenta 2022年首个10万台量产耗时24个月,而今最快不到40天即可完成10万台交付。这意味着,Momenta数据采集的“管道”正在迅速变粗。交付量越大,回传的数据越多;数据越多,模型迭代越快;模型越好,交付量越大。这是一个典型的正反馈循环。
曹旭东对此有一个判断:“整个智驾或者整个自动驾驶它有非常强的规模效应和先发优势,它的效应会比芯片行业更强……自动驾驶,因为它是软件,它的边际成本是零,所以它的规模效应更强,它的规模效应除了成本上的规模效应,还有体验上提升的规模效应。”
如果把这个判断放到数据Scaling的语境里,意思就很清楚了:当你的数据量是竞争对手的10倍时,你的模型能力可能不是竞争对手的2倍或3倍,而是代际层面的碾压。因为数据规模本身就是一个“门槛型”的竞争要素,它不像算法可以快速复制,也不像人才可以用高薪挖角。
但数据Scaling有一个前提:你得先有足够多的车在路上跑。而让车在路上跑的前提,是你得有人愿意买单。
这就是商业Scaling的意义。
曹旭东提到了一个概念叫“物理AI的门票”:要实现通用物理AI,而且一定要有大量现金流业务。
这句话点出了物理AI领域一个极其现实的困境。从数据采集、清洗、标注,到模型训练、验证、部署,世界模型的研发每一个环节都需要巨额的资金投入。没有现金流业务支撑,连“入场”的资格都没有。
Momenta的现金流业务,是它的L2++量产辅助驾驶解决方案。根据2026年6月CIC灼识咨询发布的《自动驾驶行业蓝皮书》,2025年3月至2026年2月,中国第三方城市NOA供应商市场中,Momenta市占率达65%,位居行业首位。Momenta的客户已覆盖国内全部主流乘用车企业,全球排名前10大车企中已有9家与其开展合作。
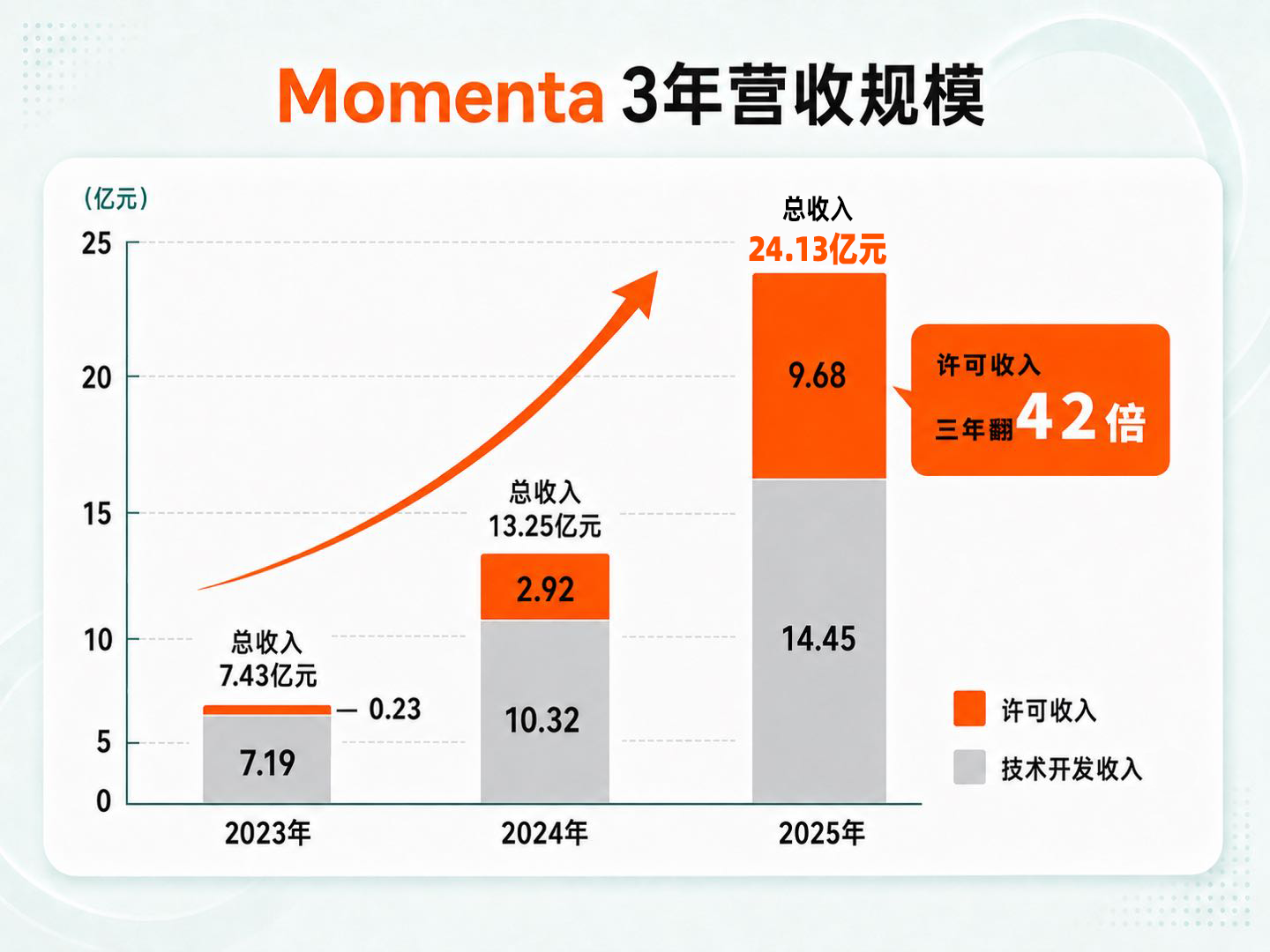
招股书显示,2023年至2025年,Momenta营业收入从7.43亿元增长至24.13亿元,三年翻三倍,年均复合增长率超80%。截至2025年底,公司现金储备超100亿元。
这些数字背后的商业含义是,L2++业务不仅创造了营收,更重要的是,它验证了Momenta产品的商业化能力。车企愿意为这套方案付费,说明它在成本、性能、交付效率上具备竞争力。而这种竞争力,又会反过来吸引更多车企采用,从而进一步扩大数据采集的规模。
商业Scaling和数据Scaling之间的互动关系,可以这样理解:L2++量产车越多→采集的数据越多→模型迭代越快→产品体验越好→更多车企采用L2++方案→量产车更多→数据更多。
这是一个双循环。商业Scaling解决的是“谁为研发买单”的问题,数据Scaling解决的是“模型如何进化”的问题。两者缺一不可。
从商业化角度看,如果聚焦自动驾驶领域,曹旭东判断:“最终全球3到4家供应商会胜出。”
如果这个判断成立,那么Momenta当前所处的阶段,就是那3到4家席位竞争中的关键卡位期。它已经拿到了入场券:120亿公里数据、65%的市占率、前10大车企中9家的合作……
“2017年奔驰就投资了我们,但我们跟奔驰的第一个量产项目上市是2025年的后半年,经历了整整8年的时间。2024年才拿到了奔驰所有的电车和油车的业务。”曹旭东曾透露。
8年时间,意味着什么?意味着从接触到合作、从POC到Pre SOP、从Pre SOP到小批量量产、从小批量到全面量产,每一个环节都是一道门槛。
一旦跨过这些门槛,客户不会轻易更换供应商,因为切换成本极高。而这种“锁定效应”叠加规模效应,会使得领先者的优势持续放大,后来者追赶的空间持续收窄。
当然,很多投资者早已意识到Momenta的这种稀缺性。Momenta的股东阵容极其豪华,汇聚了全球最核心的产业和科技战略投资人,以及全球顶级财务投资人。
产业资本囊括了全球汽车产业链的核心玩家,包括:上汽、通用、奔驰、丰田、比亚迪、现代、奇瑞等7家全球顶级车企,以及博世、德赛西威、立讯精密等头部产业链合作伙伴,和Uber、Grab、Stone Venture等Robo合作伙伴。科技巨头则包括腾讯、阿里云、蚂蚁集团、京东等。

财务投资人更是覆盖了淡马锡、IDG、阿曼投资局、亦庄国投、Granite Asia、顺为、蔚来资本、凯辉基金、云锋基金、蓝湖资本、创新工场、真格基金、鼎晖投资、高榕创投、高成资本、众为资本、愉悦资本、钟鼎资本、盈峰资本、招银国际、华泰创新资本、混沌资本、春华资本、大湾区基金、国新基金、光合创投、九合创投、锦秋基金等全球最顶尖投资机构。
超豪华、多元化的股东阵营,不仅为Momenta提供了战略和资本支持,还从业务协同、用户增长和全球化布局等方面助力了Momenta高速增长。
“一个模型打通全场景”的估值逻辑
如果只停留在“技术如何领先”的层面,就还没触及Momenta最核心的价值命题。真正的命题是:这套底层能力,能生长出多大的估值空间?
曹旭东在谈及公司L4布局时,提到了Jeff Hawkins的一个核心概念:一个神经网络、一个大模型,能够实现通用AI的能力。曹旭东将这个理念平移到了自动驾驶领域,即一个自动驾驶的大模型能够实现所有的自动驾驶的垂直应用,并且做得更好。
这句话听起来有些抽象。但曹旭东紧接着说了一句更具体的话:“这件事情我们已在Robotaxi、Robovan和乘用车上成功验证了,并且取得了很好的效果。”
验证了什么?验证了Momenta所说的“一个模型打通全场景”不是一张PPT上的蓝图,而是一个已在多条业务线上跑通的极简架构。乘用车量产、Robotaxi、Robovan这三个看似独立的自动驾驶场景,共享同一套底层模型架构。而明年,Robotruck也将加入这个序列。
这背后的商业逻辑,值得拆开来看。
先罗列一下这四块业务的体量。公开数据显示,到2030年,全球Robotaxi市场规模预计约818亿美元,中国市场约381亿美元;Robovan全球市场规模约850亿美元,中国市场约535亿美元;Robotruck全球市场规模约330亿美元,中国市场约165亿美元。

四块业务对应的市场空间,合计超过2000亿美元。但Momenta的叙事逻辑,不是“同时分别做四个生意”。如果是那样,它只是一家业务线分散的供应商。Momenta的叙事是“用同一个大脑做四个生意”。这个差异,决定了估值的量级。
传统模式下,做Robotaxi的公司做不了Robovan,做Robovan的做不了乘用车L2++。因为每一条业务线都需要独立的传感器方案、独立的算法团队、独立的数据采集体系、独立的验证流程。每个垂直场景的“know-how”都深埋在各自的组织和经验里,无法简单复制。结果就是,每一个新场景的开拓,都意味着从零到一的重复投入。
Momenta的做法完全不同。它的乘用车量产系统已在90万台量产车上跑着,积累了120+亿公里真实数据。
这些数据中包含了各种道路场景(城市道路、高速公路、乡村小路、停车场),这些场景与Robotaxi、Robovan、Robotruck所面对的道路环境,本质上是同一套物理世界。一个理解了城市道路复杂交通流的世界模型,稍加微调就能适配物流场景的路线规划。一个掌握了高速公路长距离巡航能力的模型,自然能延伸至Robotruck的干线运输。
值得一提的是,当一家公司准备上市时,资本市场会本能地寻找一个对标物。所以“XX领域的特斯拉”“中国的某某某”等尽管粗糙,却是很多科技公司在IPO招股书之外必备的身份标签。
Momenta面临同样的情况。它的业务横跨乘用车L2++、Robotaxi、Robovan、Robotruck,技术底座是“世界模型”,商业模式是“一个模型打通全场景”。这套叙事宏大而自洽,但问题是,它到底像谁?
最容易想到的对标,是Anthropic,二者同样拥有强大的基座模型,同样先在一个高价值垂直场景实现商业闭环,再向其他场景泛化扩张。
该逻辑指向的终局:曹旭东称之为“平台级系统提供商”,而非单一场景的解决方案供应商。这个定位的关键不在于当前营收的规模,而在于“一个模型打通全场景”的架构所带来的持续边际成本递减和跨场景协同效应。
Momenta的“一个模型打通全场景”,在自动驾驶领域复制了同样的平台效应。乘用车量产的数据和经验,可以直接帮助Robotaxi优化城市复杂路口的决策;Robotaxi在L4级无人驾驶中积累的长尾场景处理能力,可以反哺乘用车L2++的安全冗余;Robovan和Robotruck在物流场景中的路径规划经验,又可以提升乘用车在高速场景的续航效率。
这形成了一个跨场景的正反馈循环。场景越多,大模型见过的“物理世界”就越丰富;大模型越强大,每个场景的落地成本就越低、效果就越好。
这种边际成本的骤降效应,是Momenta估值逻辑中一个容易被忽视但至关重要的支点。华尔街对平台型公司的估值溢价,从来不来自当前营收的简单乘数,而来自新增业务线时那一根几乎水平的边际成本曲线。
总之,Momenta的估值逻辑,既不能用传统的汽车零部件供应商来套,也不能简单地用AI软件公司来估。它更像一个正在被建造的物理AI平台,底层是理解物理世界的世界模型,中间是跨场景复用的All-in-One架构,上层是正在逐步打开的一个个垂直应用场景。平台的每一层,都在为下一层的扩展降低边际成本。
至于这个平台的终局价值,那取决于它最终能覆盖多少个“需要与物理世界交互”的场景。乘用车、Robotaxi、Robovan、Robotruck是已被确认的前四个。
至于机器人,曹旭东判断“还需要一段时间”。不过,机器人与汽车的底层逻辑是相通的。毕竟,一个掌握了物理世界普遍规律的模型,理论上可以泛化到任何需要与物理世界交互的载体上。
凯辉基金创始人及董事长蔡明泼表示,作为坚定的长期主义者,凯辉很荣幸能够在自动驾驶最跌宕起伏的十年里,持续陪伴Momenta一路成长。我们见证了团队用极强的战略定力和极致的研发能力,逐步将“世界模型”打磨成物理AI商业护城河。自动驾驶是构建未来智能社会的关键路径,我们期待Momenta继续依托其技术积累、量产能力与全球生态,在AI技术出海浪潮中以“中国方案”推动全球物理AI产业的进步。